2024-07-29_FlexAttention for Efficient High-Resolution Vision-Language Models
| arXiv Fulltext PDF| 2024-07-29 | Junyan Li, Delin Chen, Tianle Cai, Peihao Chen, Yining Hong, Zhenfang Chen, Yikang Shen, Chuang Gan | URL | ECCV24
核心思想:
- 根据Last Text Token对低分Image Token的Attention Score,决定下一层需要的High-Resolution Feature
- High-Resolution Feature只作为Self Attention的KV,相当于Cross Attention
#问题 训练数据用的啥?训练和推理的last text token的不一致咋解决?
1 Method
前Nfa层:普通Self Attention只输入低分+text
后Nsa层:Hierarchical Self-attention Module
- 低分&Text as Q
- 低分&Text&上一层选择的高分特征 as KV(高分特征使用单独的KV投影矩阵)
如何选择下一层需要的高分特征:根据Last Text Feature对所有低分Image Token的Attention Score,设置Threshold过滤,得到低分token,选择对应的高分区域的token
#idea 我想的是(对Attention Map做插值,也差不多)
- 选择10%左右的高分token
- 第一层Hierarchical Self-attention可以直接用来自最后一层普通Attention的Feature Map来选
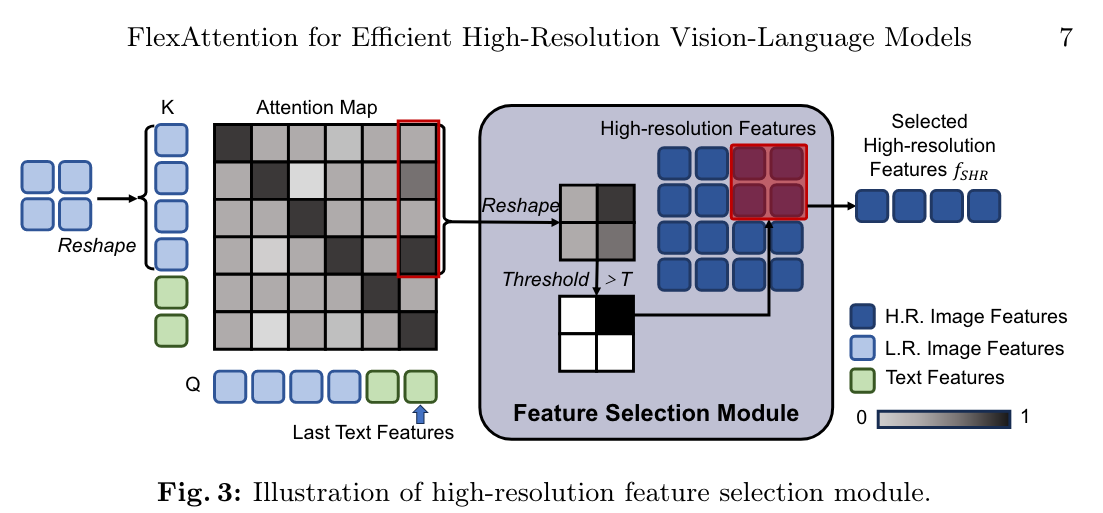
2 实验设计
分辨率1008x1008
baseline:
- 448x448的LLaVA-HD(切分子图,基础分辨率224)
- 基于CogAgent实现的LLaVA-XAttn,即Cross Attention注入高分特征,分辨率1008x1008
三个模型均Finetuned from LLaVA-1.5-7b
V* Bench [53], MagnifierBench [27], TextVQA [45] and RSVQA-HRBEN [38]. The first two benchmarks focus on evaluating the model’s capability on general highresolution VQA, while the last two benchmarks focus on evaluating the model’s performance on domain-specific high-resolution VQA such as TextVQA for text understanding and RSVQA-HRBEN for remote sensing.
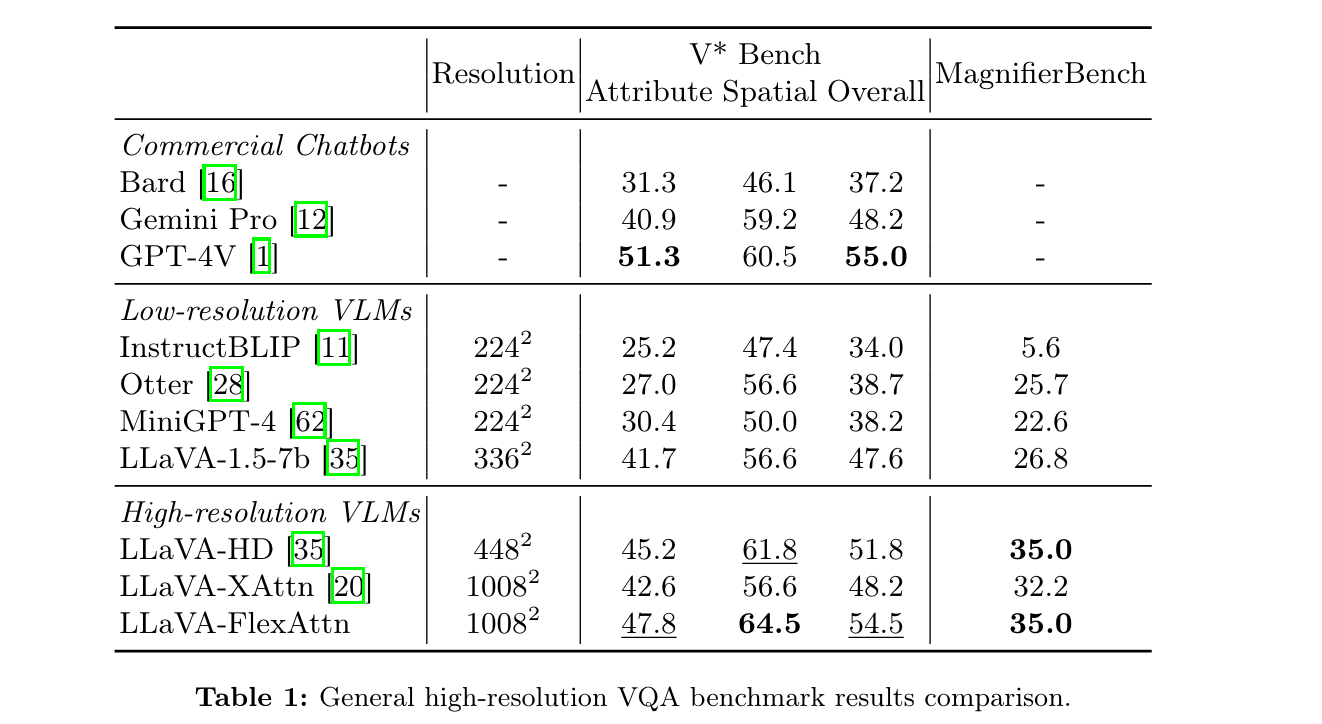
效果:不如我们的HD Baseline!TextVQA和Vstar都不行!原因?
- 高分token数量太少?
- 因为高分token不能传到下一层去,直接插入不太够?
- 还是因为根据上一层attention score筛选不行?
- 训练和推理不一致,训练应该用的是GT answer的最后一个token的attention score,这个应该不合理?
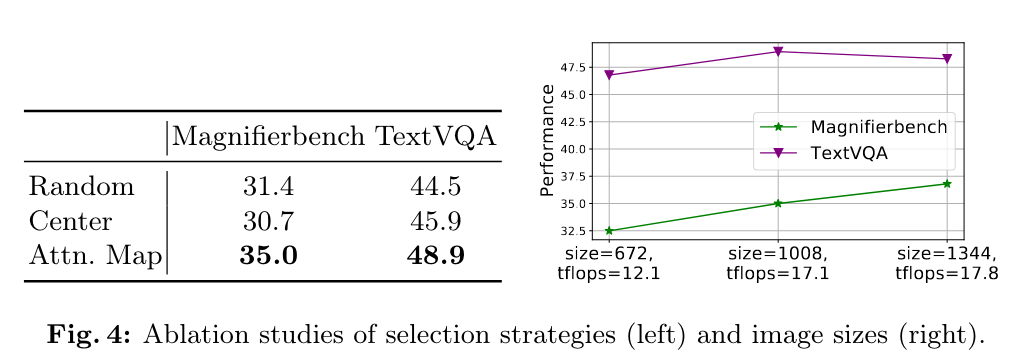
2.1 消融
基于Attention Map筛选的优势, 以及基于Image Size做消融。
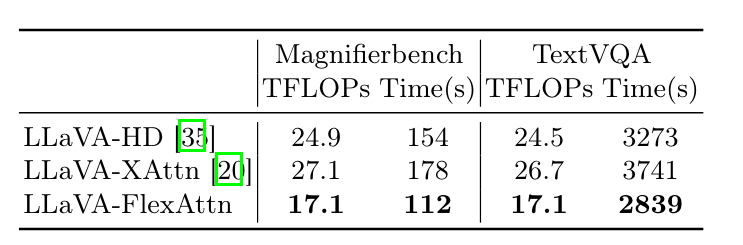
2.2 Inference对比
3 分析
优势:用了类似Cross Attention的机制节省开销,确实做到了开销基本没变!!
劣势:
- 如果要基于last text token不断剪枝, 推理就不能用KV Cache!用了KV Cache的话还会基本没变吗?
好处是,这个东西做高分,然后在VStar和MagnifierBench上测,被认可了。其他benchmark不怎么掉点就行。
4 Abstract
Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.